Programming Principles
May 30, 2023
Computation is at the heart of what we do. We write computer programs for running simulations of physical systems, training Machine Learning models, automating tasks or simply testing new ideas. In this blog post we share the programming principles that we try to follow to make fast progress on our goals, while maintaining high standards on the quality of our code.
Principles:
- Tracer Bullets
- Readability first
- Simplicity
- DRY: Don’t Repeat Yourself
- Don’t write “scripts”
- Write Unit Tests
- Manage Technical Debt
- Don’t Reinvent the Wheel
Tracer Bullets
In The Pragmatic Programmer book, the authors talk about Tracer Bullets in the context of:
building an architectural prototype - a bare-bones skeleton of your system that is complete enough to hang future pieces of functionality on. It’s exploratory, but it’s not really a prototype because you are not planning to throw it away - it will become the foundation of your real system.
In other words, build something simple that goes “end-to-end”, as this will remove a lot of the uncertainty regarding feasibility and whether some layers or components of the system will be adequate. Once you have this: consolidate it into something leaner, cleaner and extensible. Finally, expand the system by adding more features.
For example, if you are doing Machine Learning experiments: start by having a very simple dataset, a very simple model (e.g., an MLP) and a simple training loop, that already trains and computes some metrics. Now you can expand it to define a more complex model, training on a larger dataset, adding support for multi-GPU training, etc, etc. But you will always have “something” working end-to-end. Besides, you will have the simple baselines implemented from the beginning, and you can then easily compare with them!
Consider the alternative: you build a system, by completing each layer before starting the next one: first you implement a very scalable way to deal with the dataset, then you implement a state-of-the-art neural network architecture, then you implement the loss functions, metrics and visualizations, even a distributed training framework, until finally, after many weeks, you have something working… or not! Often the results are not what you expected and there is a bug somewhere (and now it’s too complex to debug!), or you made a wrong assumption about the data, or maybe you committed to a framework too early… This will be frustrating, because you have wasted a lot of time working on this. You could have probably discovered those problems earlier!
Readability first
Granted, you write code to be executed by computers. But first of all, you write code to be read by your fellow human teammates!
Therefore, you should maximize readability and maintainability, instead of “cleverness”, and you should not apply small performance optimization tricks that make your code harder to understand!
Remember what the legendary computer scientist Donald Knuth once said:
Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
Here are a couple of aspects you should prioritize to make your code more readable:
Small functions - do not write long functions or methods with a lot of unrelated logic in one single place. If you find yourself dividing sections of your code with lines of comments like “# read input data”, then “# pre-process data”, etc. this is a strong indication that you should have smaller separate functions for those subtasks. This way your code is easier to understand, and those functions can be reused in other places. They can also now be properly unit tested!
Meaningful names - the choice of names for variables, methods, functions, classes, modules and packages, is very important. A variable called “p” can be anything, but if you call it “protein” or “particle”, you are helping the reader understand your program by using terms that are both familiar and specific.
Simplicity
Below is an often-shared cartoon illustrating in a funny way how code complexity evolves through the years of experience of a programmer. In the beginning one writes very simple code, but one can not yet tackle large problems. The slightly more experienced programmer is likely to “over-use” Object Oriented Programming (OOP) concepts and “Advanced Design Patterns”, creating too many layers of abstraction and indirection, and also inadvertently creating code that is harder to understand (for everyone else, of course!).
The last stage is one in which the programmer becomes able to solve complex problems, while writing simple and elegant solutions.
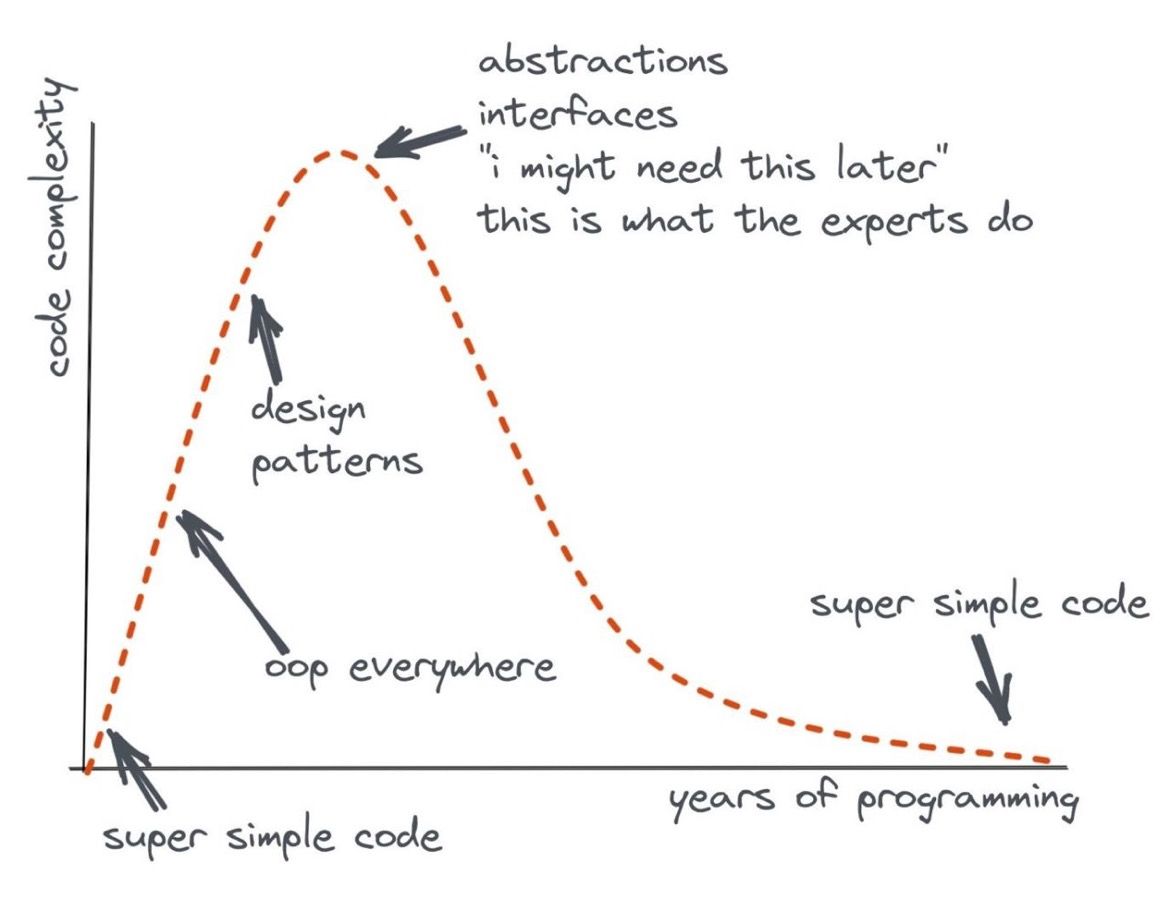
Figure 1 - Code complexity as a function of programmer’s experience [original source: unknown]
The take-home message here is twofold:
If you are a developer with some experience, don’t try to differentiate yourself from more junior programmers by writing code that is so “advanced” that actually becomes unnecessarily hard to understand. A much better sign of mastery is to solve the problem at hand, while keeping things as simple as possible.
Simplicity might not be easy to achieve: it may be equivalent to solving a very difficult search problem! Think of the combinatorial space of all possible computer programs: which is the simplest one that solves your problem? This might be hard to find, much like discovering short and elegant proofs for Math theorems is harder than just finding “any” proof.
As a programmer who cares about your craft, it’s your role to keep simplicity in mind.
DRY: Don’t Repeat Yourself
If there is a guiding principle that will guarantee you a huge increase in code quality, it’s the “DRY Principle”:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
- Andy Hunt and Dave Thomas, The Pragmatic Programmer.
As an example, you should always try to avoid “copy-pasting” code from one place to another, and make an effort to consolidate logic into a single location (e.g., a simple function), that can be reused in multiple places. If your code has a lot of duplication, something is wrong, and it should be refactored.
Duplication also happens when you write documentation that is just repeating what the code already says, for example when you have a for loop, and you add a comment like “#iterating over the elements of the list”. The comment is not adding much, and if you now change the code, you would need to change the comment too. Comments should provide complementary information at a different level of granularity from the code itself (e.g., point to a research paper describing the algorithm, or highlighting a non-trivial design decision you had to make).
Don’t write “scripts”
A common “anti-pattern” that we would like to avoid is when your code is implemented as a long “script” that will perform some task. It typically goes like this:
def main():
# load some data...
# pre-process the data...
# define the model architecture...
# output metrics...
# generate visualizations...
Your script works, but you need to ask yourself several additional questions, regarding code quality and structure:
Is it reusable?
Not really. Some of that logic, like preprocessing the data, or generating visualizations, could be useful for other people / projects, but you can’t reuse it, because it is not written in separate functions, and it is not inside a python module that you can import from other python programs. It is just a big blob of code inside the main function of your “script”!
Is it testable?
Not really. For the same reasons: you don’t have cleanly defined functions, you can not write unit tests to test them independently.
Is it easily maintainable?
Not really. If I find a small bug on one of the sections, for example the visualization at the end, I can not easily test it independently, and I would have to run the whole script (training an ML model!!) just to check if the modification I did to my plot works. This is insane!
Please resist the impulse of writing new functionalities as yet another long Python script. Write your functions inside reusable python modules, and let your script be very simple: it will import the modules and the main() will invoke the functions passing the command line flags as arguments.
Write Unit Tests
A good way to ensure that your code has some desirable properties is to write unit tests for it. Why? Ideally you want your code to be:
- Correct: your code outputs the desired results
- Modular: it has functions with clear interfaces that can be combined
- Reusable: functions can be imported by other programs, and still work (i.e. they don’t rely on global variables, or other context that is hardcoded in a specific script)
- Readable: one should be able to tell what each function does, ideally in a self-explanatory manner, without a lot of additional documentation
- Fast: it runs fast enough. Note that this came last!
Unit tests help with all of these!!
You can only write unit tests if you have defined functions with a clear interface (modular ✅), and that can be imported by other programs (i.e. your unit test file) (reusable ✅). By providing a series of expected inputs and outputs you will make your code more readable and self-explanatory ✅, and obviously you will be checking whether it is correct ✅! With some benchmarking features of popular Python unit test libraries, such as pytest, you can even check how fast your implementation is ✅!
If you never wrote unit tests with pytest before, consider reading the following tutorial .
Manage Technical Debt
“Technical debt” is created when, in order to achieve an immediate goal, a developer takes some shortcuts that reduce code quality. In other words, when a new feature is implemented in a “hacky way”, with poor engineering standards, just to make it work. If unaddressed, as time goes by, more of these “hacks” will accumulate and technical debt will increase further.
It is important to understand that having technical debt is a “normal” aspect of software development: it happens in every real-life software project. The secret is to manage it wisely and keep it under control.
The analogy with “debt” and taking a bank loan is actually adequate. In some circumstances, it is very rational to take a loan, and use the money for something that will have much bigger pay off than the interests you need to pay to the lender. For example, imagine you are running a small business and you already have a lot of demand from users, but you are unable to fulfill it due to your small scale infrastructure. If you take out a loan to buy more machines that help you fulfill that demand and you vastly increase your profits, then your business will accelerate. As the sales increase, you might be able to quickly pay-off your debt.
Similarly, when you have a deadline for a demo of your product, you might not have the time to make the best implementation, and you can consciously decide to temporarily compromise some of the engineering under the hood. This will contribute to increasing the number of users, getting additional traction on the market, and potentially make your project much more successful in the long run.
However, what one can not do, is to never pay back that debt and keep accumulating it. This is a recipe for disaster, as refactorings will be harder and harder! As part of your development cycle, you need to constantly allocate some time to refactor your code, without adding new features. Just clean up, re-organize, and pay up technical debt regularly (e.g., once a week).
Don’t Reinvent the Wheel
A very common pitfall for engineers, even relatively experienced ones, is the urge to reimplement functionalities from scratch when well-maintained, mature open-source alternatives already exist. This temptation is dangerous because it greatly increases the cost of developing and maintaining software, and significantly slows down the speed at which a team can deliver value.
The most effective engineering teams understand the importance of “building on the shoulders of giants.” Rather than spending weeks or months reimplementing something that already exists, they leverage existing open-source libraries and tools as building blocks — like Lego pieces — and focus their energy on writing the software that is truly their core business: the thing that differentiates them and that they care about most.
One common reason why engineers fall into this trap is that existing packages don’t provide the exact functionalities needed, or their interfaces don’t perfectly match the project’s existing data structures. Because the fit is not exact, the natural instinct of a proficient programmer may be to reimplement everything so that the new code perfectly matches the existing need. This is frequently a trap. Adapting your code to work with a well-tested external library is almost always a better investment than building and maintaining your own version. Confronting ourselves with the possibility of integrating external software can actually be an opportunity for rethinking and improving our own implementations.
In short: don’t spend your precious engineering time rebuilding what others have already built well. Use those existing tools as your foundation, and dedicate your effort to the problems that only you can solve.
Conclusions
Independently of whether you are writing production code or research code, following well established programming principles and best practices can maximize your impact.
Originally published in May 2023. Updated in June 2026.